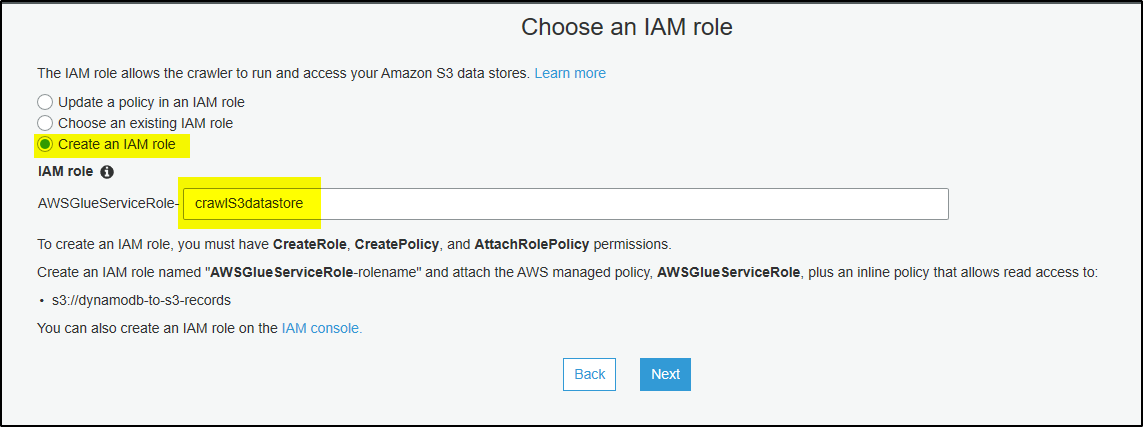
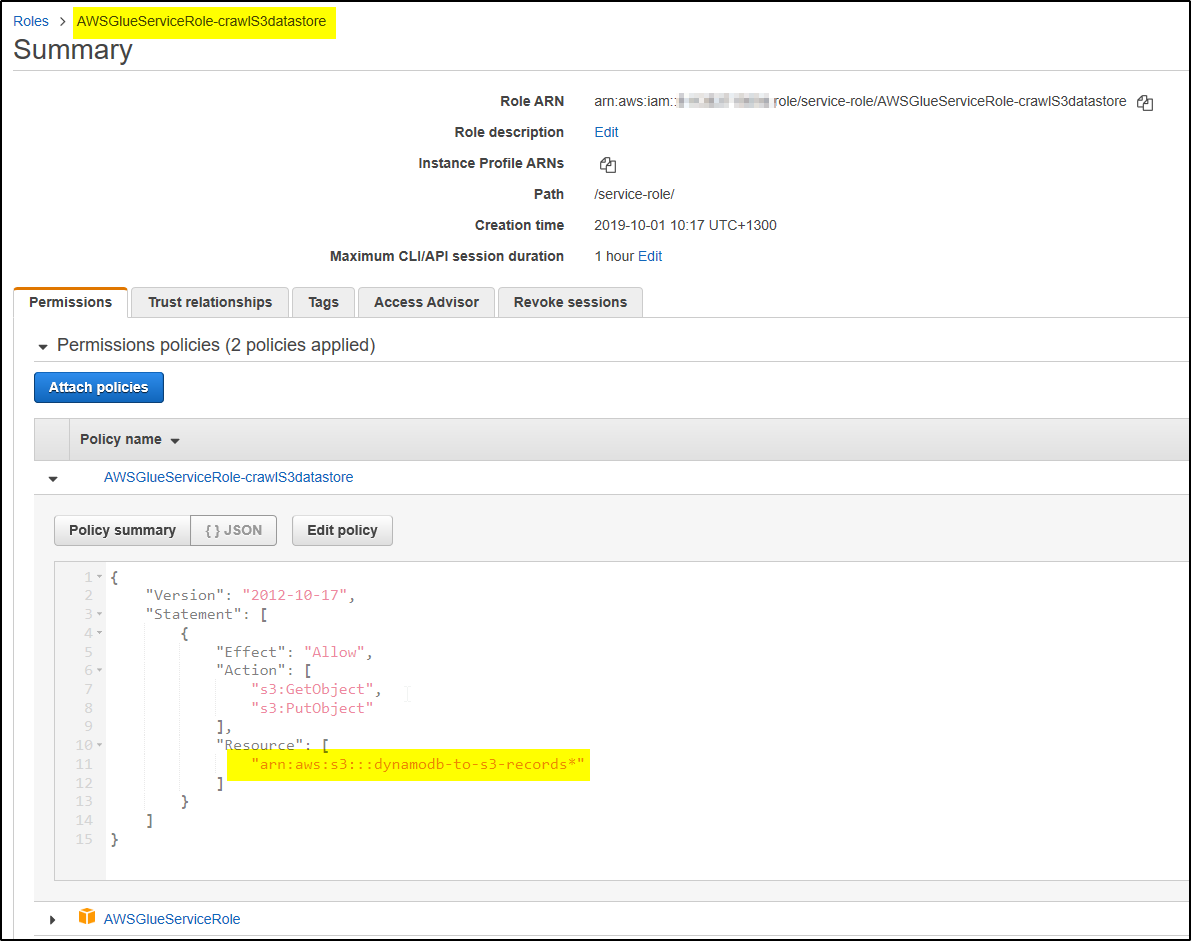
To crawl Amazon S3 or Amazon DynamoDB data store, crawlers require AWS Identity and Access Management (IAM) role for permission to access the data stores. The role provided to the crawler must have permission to access Amazon S3 paths or Amazon DynamoDB tables that are crawled.
Note: this article assumes that DynamodB tables or S3 bucket to be crawled are already created.
Step 1 – Login to AWS Glue console through Management console
Step 2 – Select Crawlers –> click on add crawler
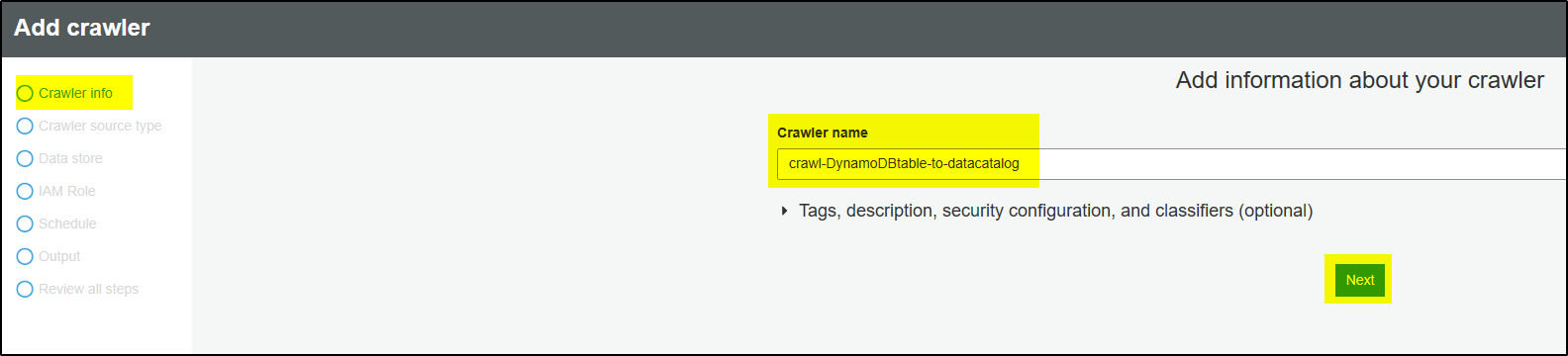
Step 3 – Provide Crawler name and click Next
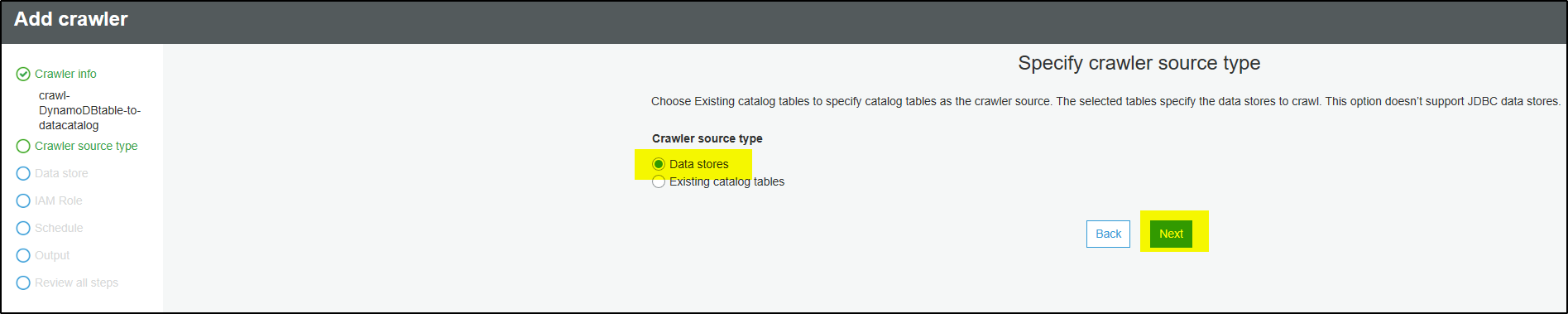
Step 4 – Choose Data stores and click Next
Step 5 – Choose data store as DynamoDB and select the Table Name to be crawled and click Next.

Step 6 – Leave default and click Next (If you want to add more tables to be crawled then click Yes and select the table)

Step 7 – On this new screen IAM role will be assigned to the crawler to access the DynamoDB tables. Select option “Create an IAM role” and provide role name. It will create the role and provide access to only the tables which crawler needs to crawl. Click Next.
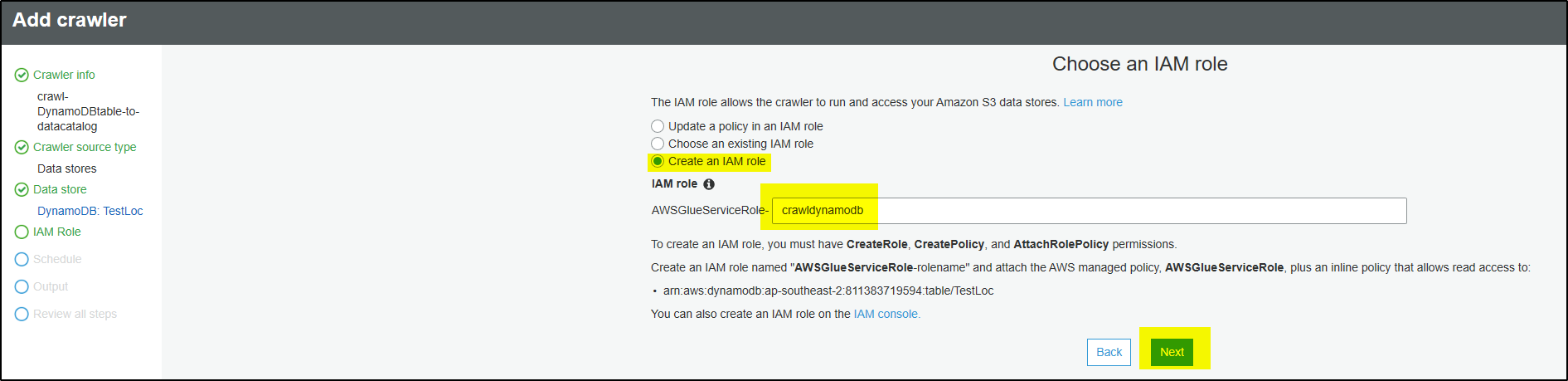
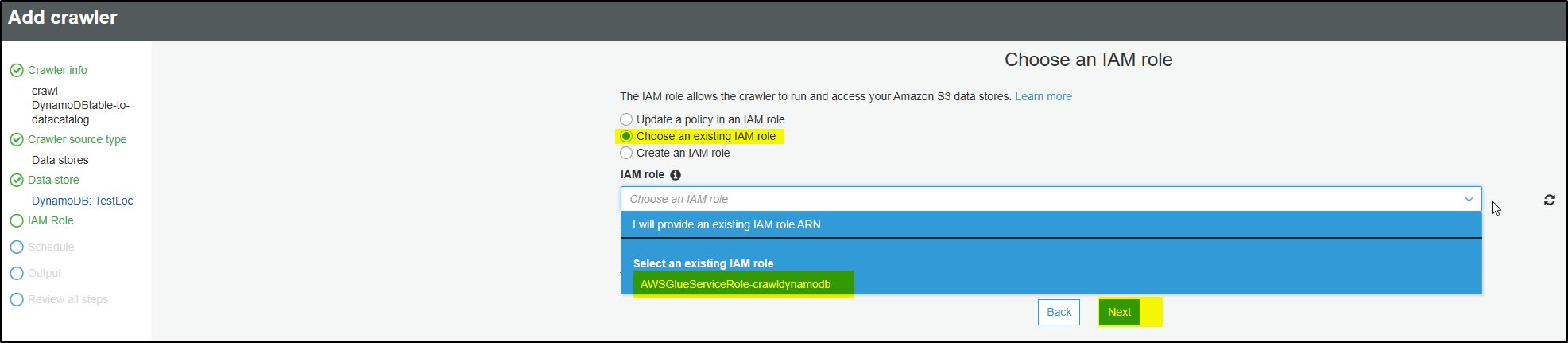
In case clicking Next doesn’t move the screen then select option “Choose an existing IAM role“. you will find that the role was created and will be displayed for selection. Select the role and click Next.
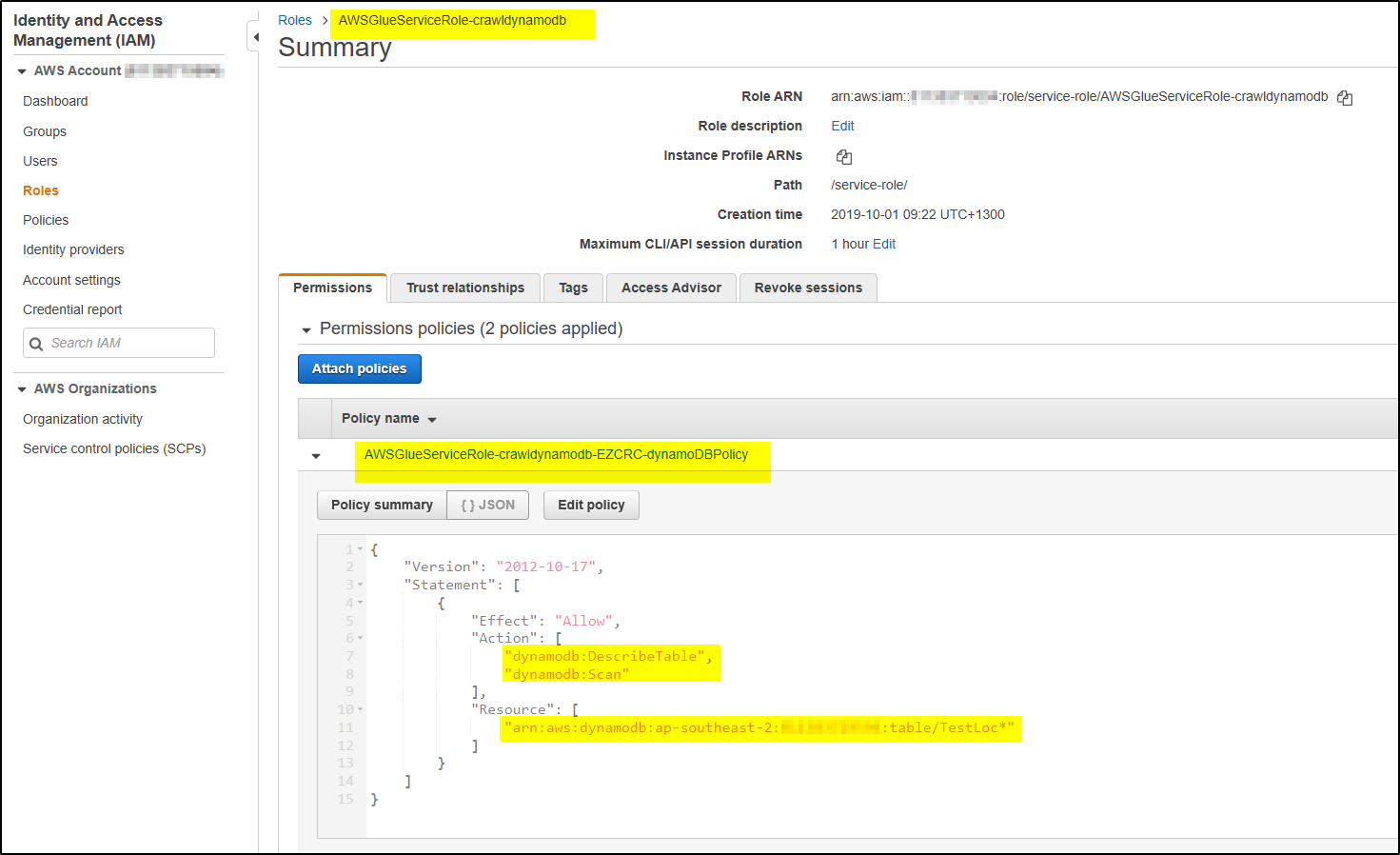
Also you can search the Role in IAM and verify the resource action allowed in DynamoDB.
Step 8 – Leave default and click Next (you can schedule how frequently you want to run the crawler)
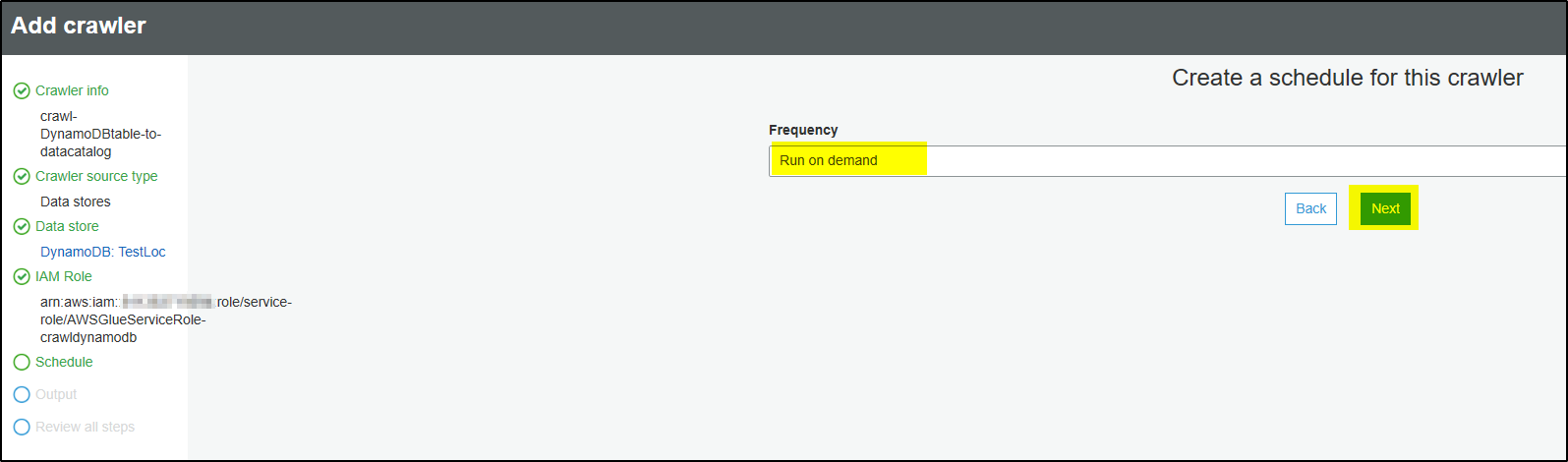
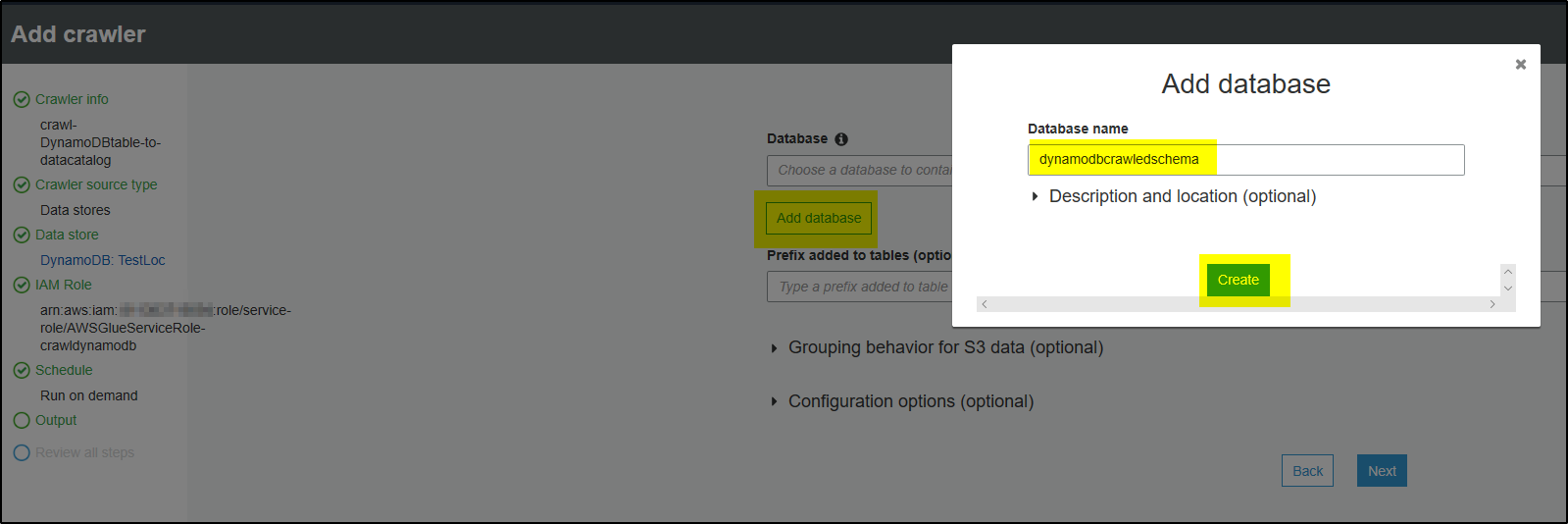
Step 9 – After crawling the DynamoDB table, crawler will create output and save it in database and tables in Data Catalog. Click Add database to add database name. Click Create. Provide any Prefix to be added to table name within the database.
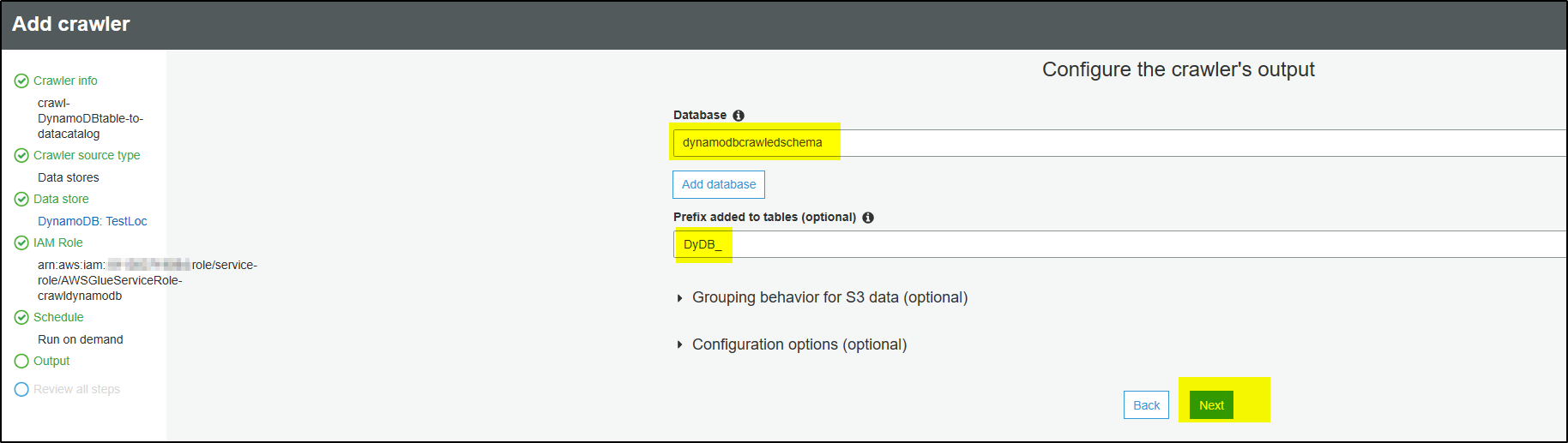
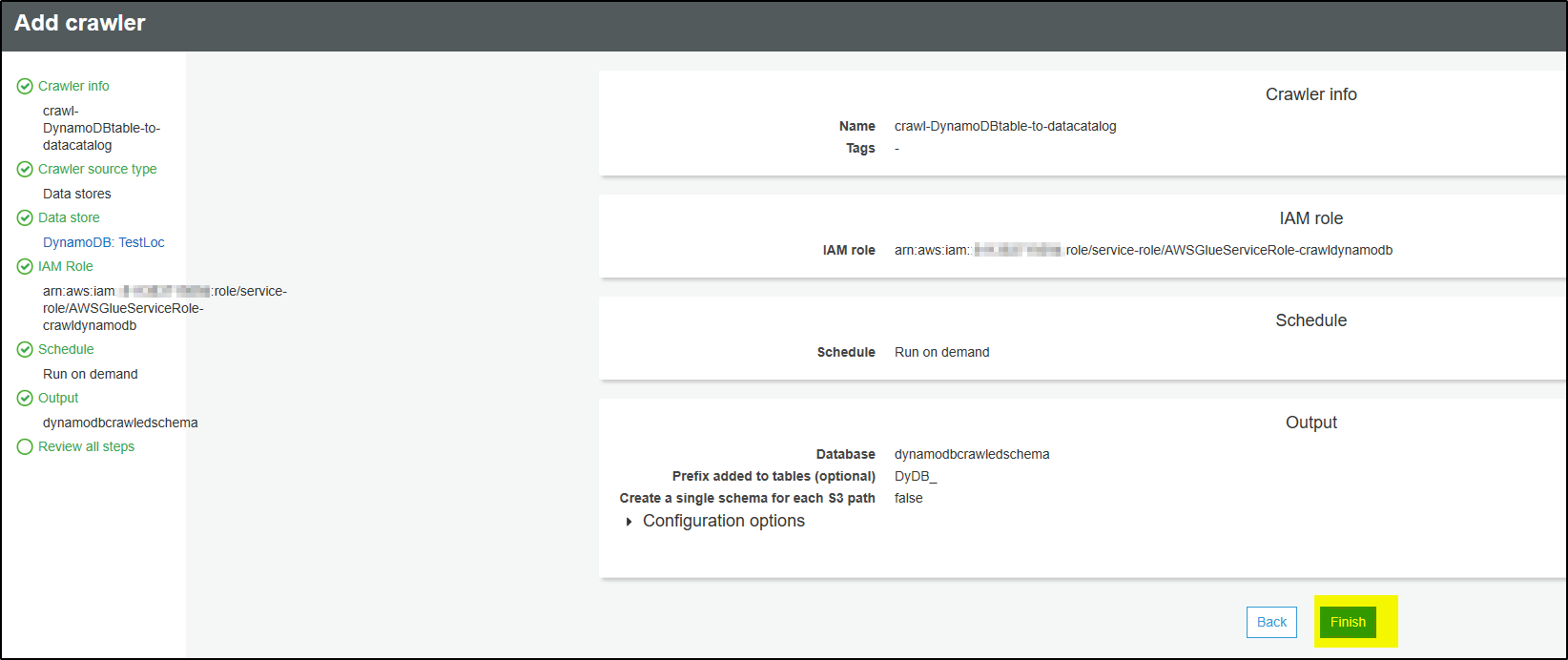
Step 10 – Review all steps and click Finish.
Step 11 – The newly created crawler will show up like below. Select the crawler and click on Run crawler. The crawler will crawl the DynamoDB table and create the output as one or more metadata tables in the AWS Glue Data Catalog with database as configured.
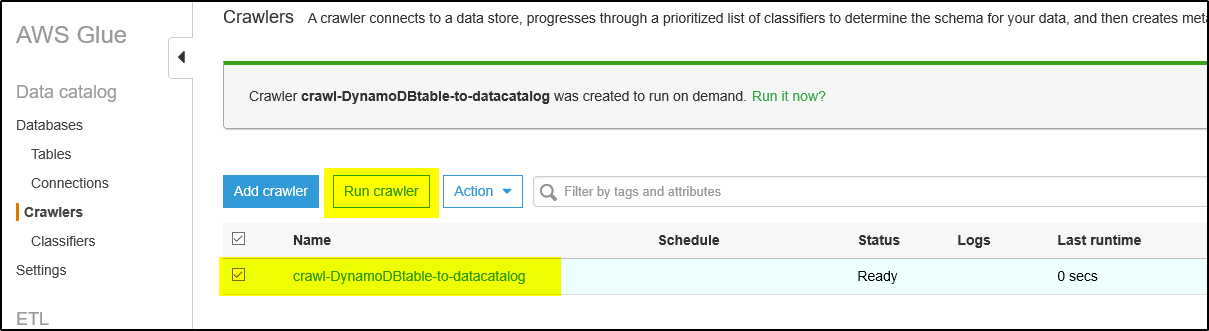
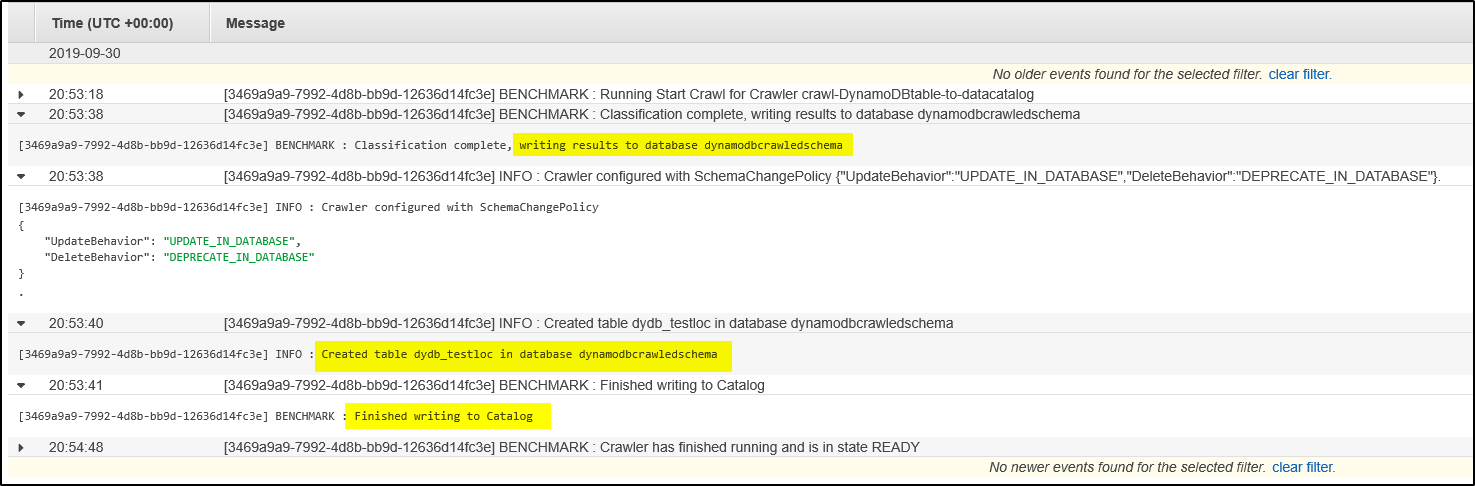
Step 12 – To make sure the crawler ran successfully, check for logs (cloudwatch) and tables updated/ tables added entry.

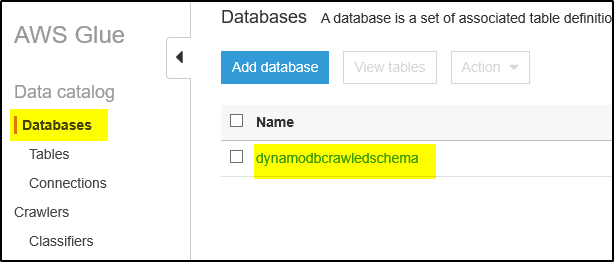
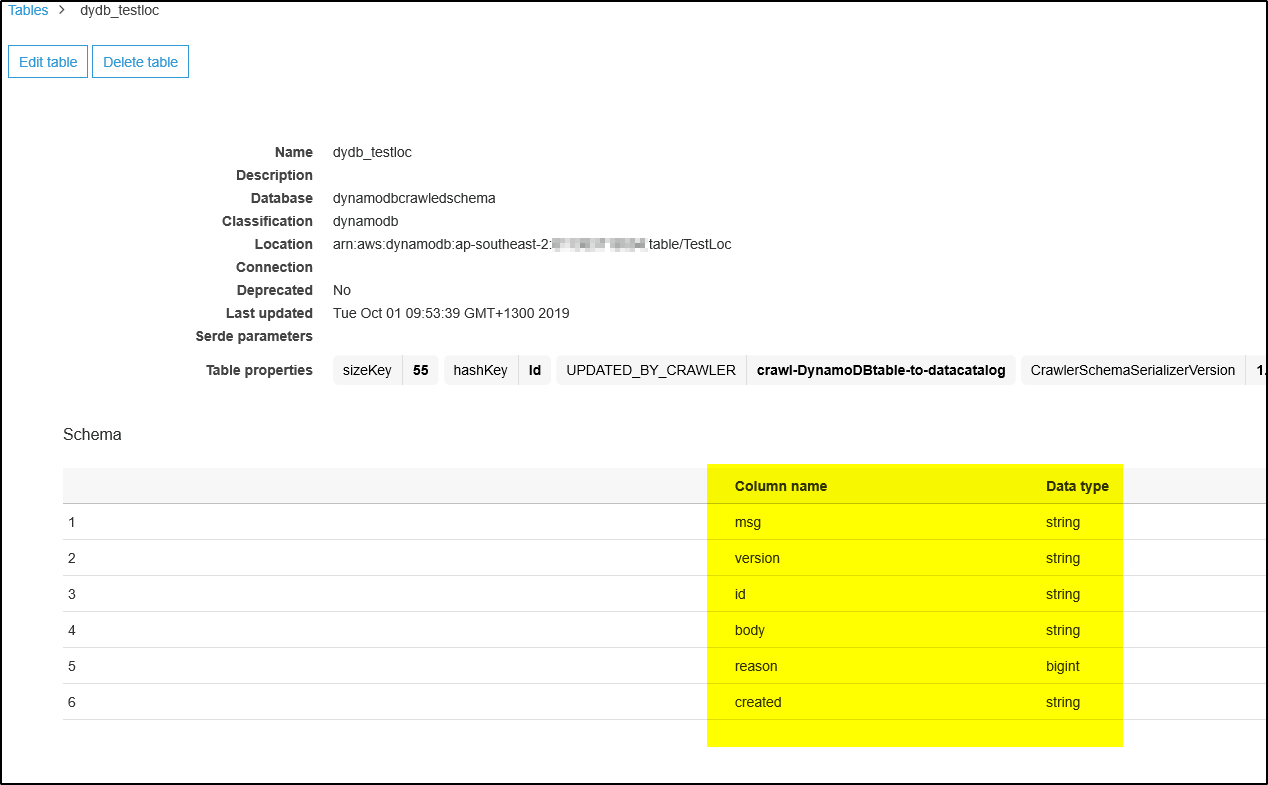
Step 13 – Now select Databases and click on the database created by crawler. Then click on link “Tables in <DB name>
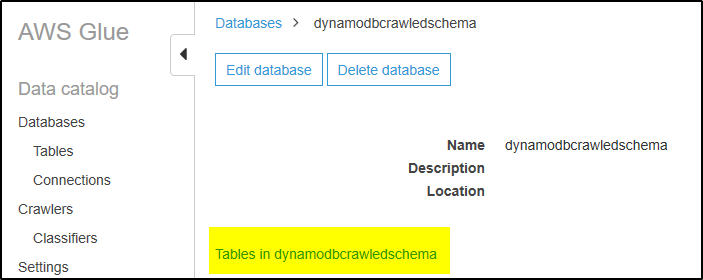
Step 14 – IT will show the table created with schema info. This Database and Table will be sued by Kinesis Firehose Delivery Stream to format the JSON record received from DynamoDB.

To Create a Crawler to crawl S3 data store
The steps are almost similar to DynamoDB data store, change
Step 5 – Select S3 as data store and provide bucket name which stores data
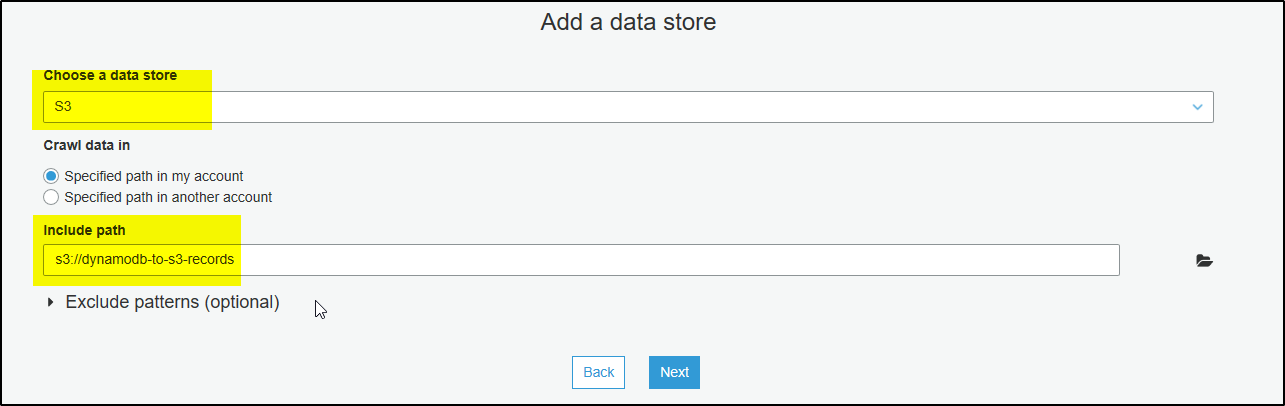
Ste p 7 – The New IAM role created will have access to this S3 bucket.