If you want to give AWS Glue & Athena in AWS account access to an object that is stored in an Amazon Simple Storage Service (Amazon S3) bucket in another AWS account then follow the steps provided.
Say, we have two accounts – Account A and Account B.
Account A–
>>S3 in account A is having a bucket ‘s3crossaccountshare’. It holds an object ‘Athena_access_test.csv’ file with data in it. To share this S3 bucket to another account, create bucket policy for this bucket-
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SID",
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::"REPLACE ACCOUNT ID of ACCOUNT B here":root",
"arn:aws:iam::"REPLACE ACCOUNT ID of ACCOUNT B here":role/GlueaccesstoS3"
]
},
"Action": [
"s3:Get*",
"s3:Put*",
"s3:Delete*",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:ListBucketVersions",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::s3crossaccountshare",
"arn:aws:s3:::s3crossaccountshare/*"
]
}
]
}
Make sure you provide the account id of account B in this policy. You can get the account id of account B in the ARN of the ROLE-
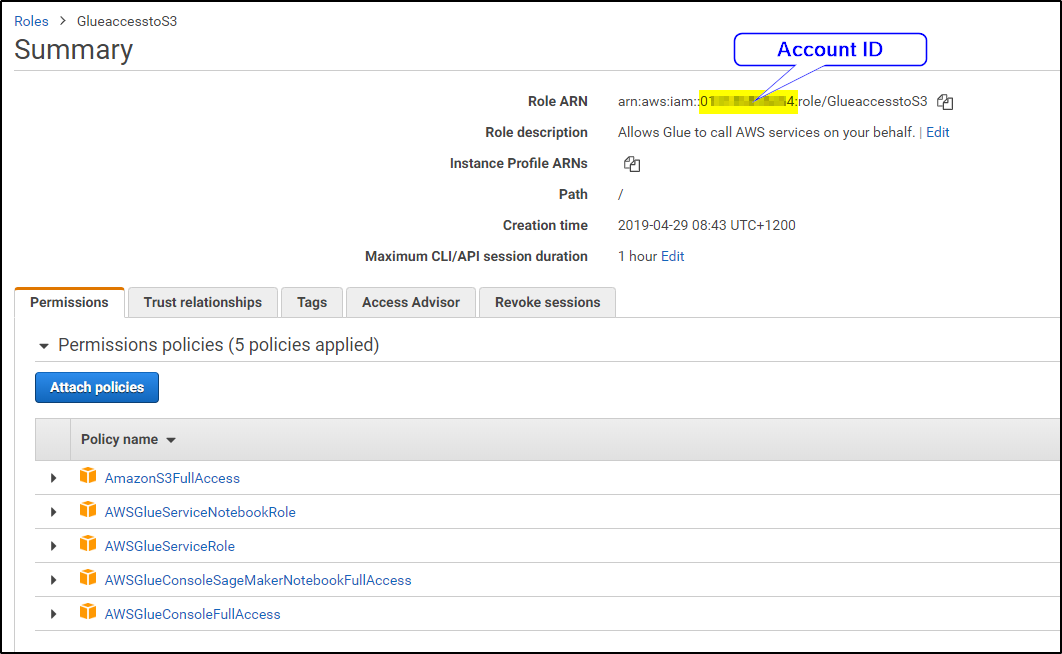
The bucket policy in Account A will look something like this after the changes-

Account B–
>> Create a Role ‘GlueaccesstoS3’ providing full access to S3 and Glue service.
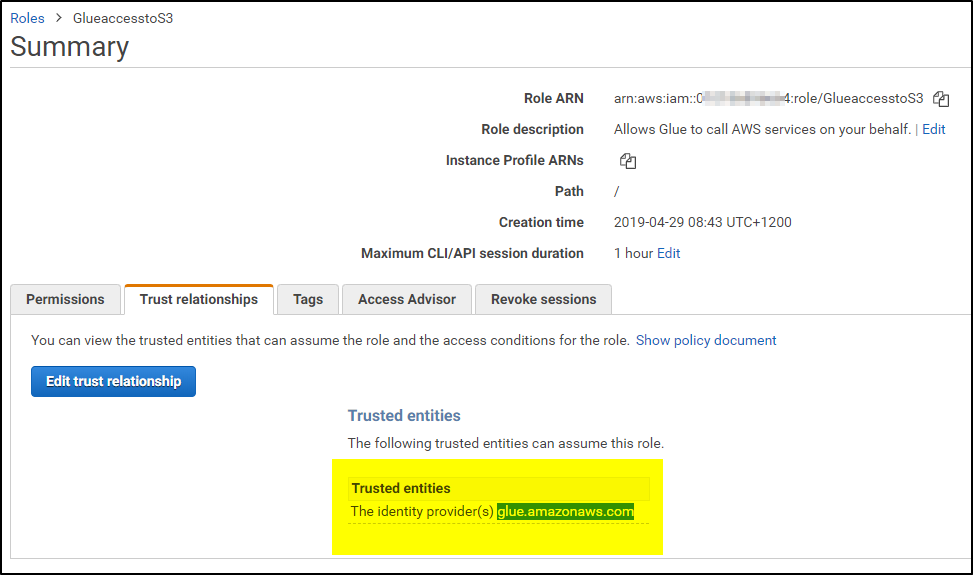
With this the setup is ready not to access S3 bucket/objects from Glue service in another AWS account.
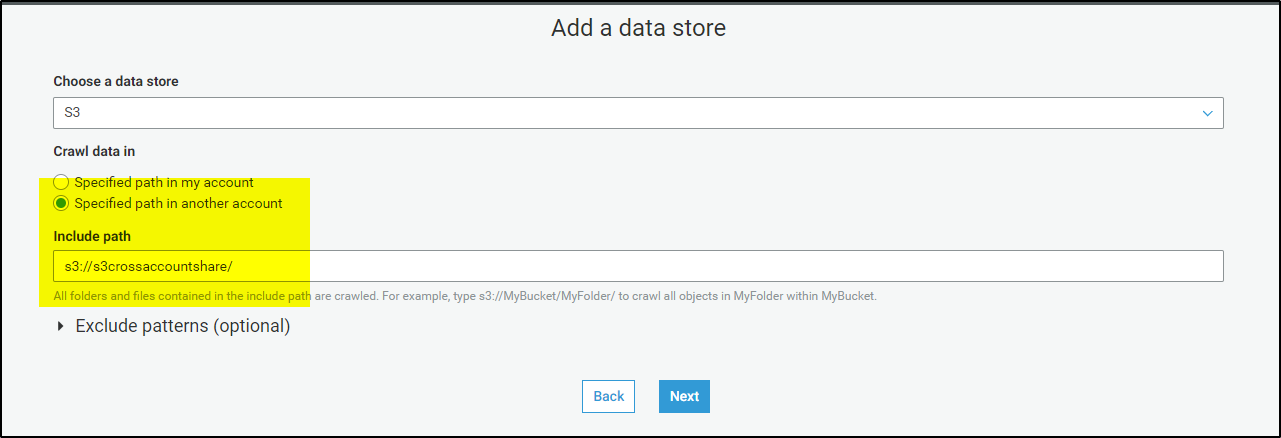
Login to Account B (where AWS Glue service) to create a crawler in Glue to access S3 objects-
>> Leave all options as default and make changes to only following screen while creating the crawler-
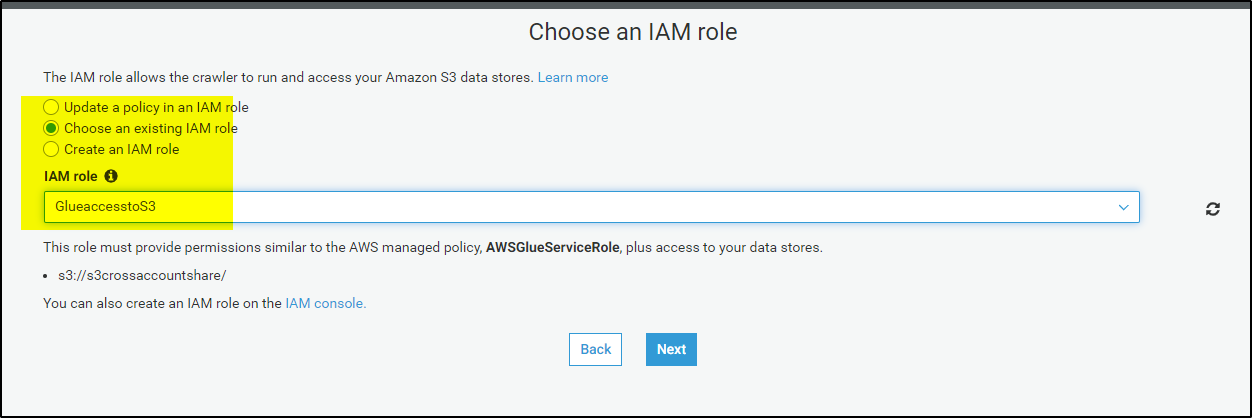
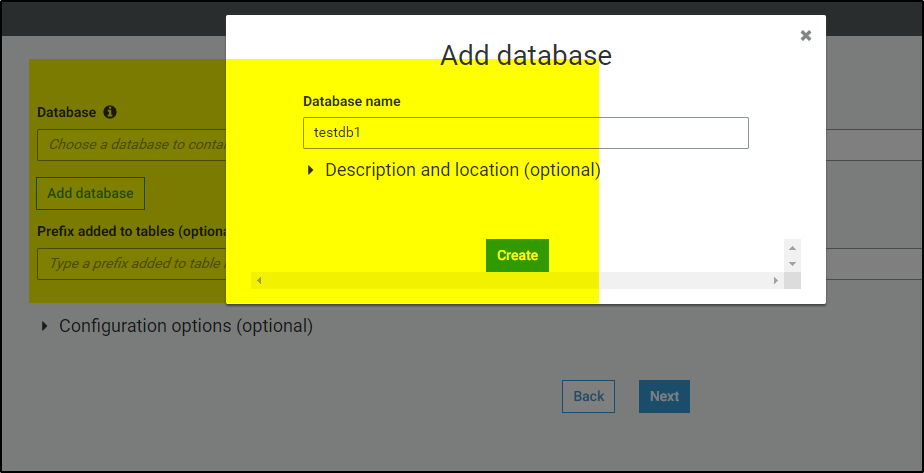
>>Run the crawler, if successful it will show the results like below-

Also you can check the Cloudwatch logs by clicking the Logs link-
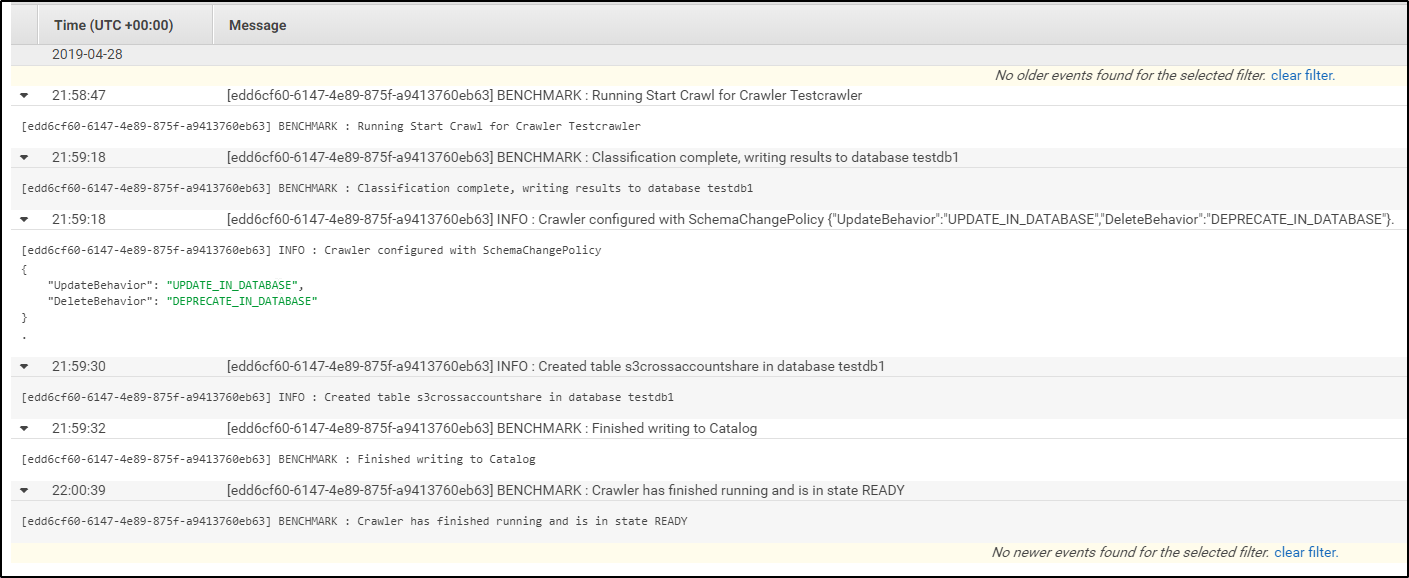
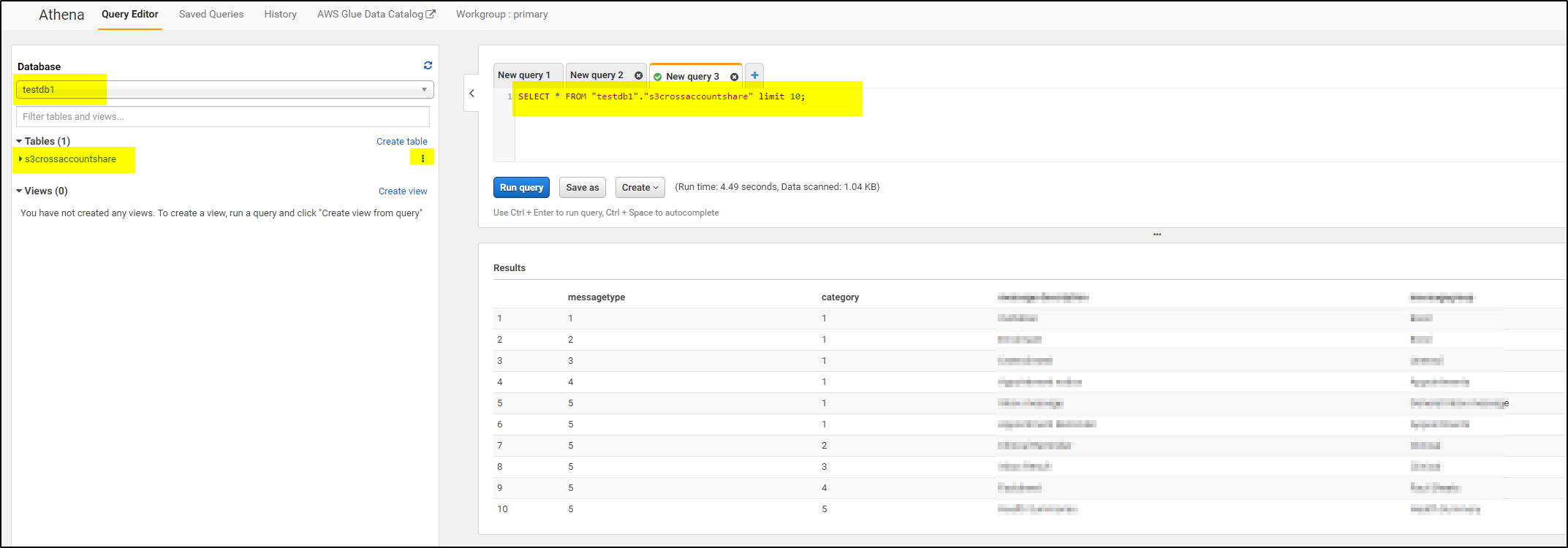
Now you can try to access the testdb1 database from Athena in this Account B–