You have data in AWS DynamoDB (NoSQL) and would like to analyse it using Microsoft Power BI. We will see how this can be achieved by using serverless architecture.
Solution:
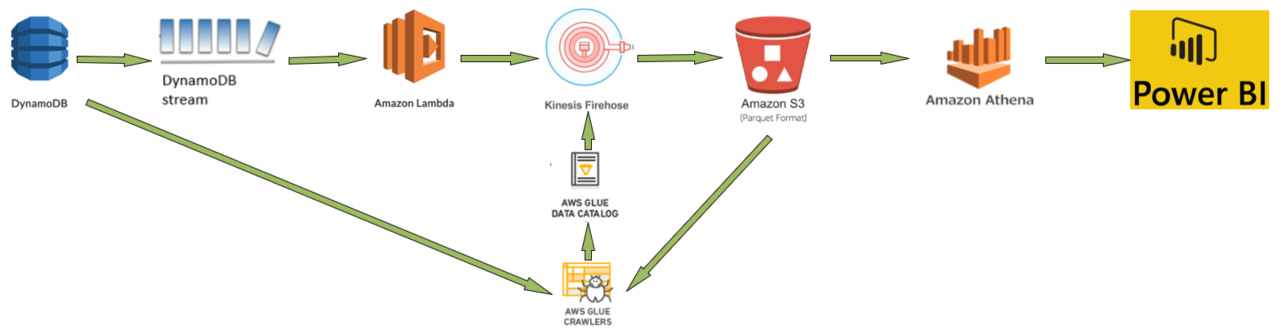
>> Activate DynamoDB Streams on your DynamoDB table.
>> Create Firehose delivery stream to load the data into S3. (S3 bucket should be created to receive data).
>> Create Lambda function to poll the DynamoDB Streams stream and deliver batch records from streams to Firehose.
>>Define a crawler to populate your AWS Glue Data Catalog with metadata table definitions. You point your crawler at a data store, and the crawler creates table definitions in the Data Catalog.
>> Create Athena standard SQL queries to analyse S3 data.
>>Connect Microsoft Power BI to Amazon Athena using Athena ODBC driver to create and publish report.
Here’s how the solution works:
- Create DynamoDB table and enable DynamoDB stream. S3 bucket to store data from Kinesis Firehose is created.
- Create a AWS Glue crawler to populate your AWS Glue Data Catalog with metadata table definitions. You point your crawler at a data store (DynamoDB table), and the crawler creates table definitions in the Data Catalog. This table schema definition will be used by Kinesis Firehose delivery Stream later.
- DynamoDB Streams is the data source. A DynamoDB stream allows you to capture changes (INSERT, MODIFY & REMOVE) to items in a DynamoDB table when they occur. AWS Lambda invokes a Lambda function synchronously when it detects new stream records.
- The Lambda function buffers items newly added to the DynamoDB table and sends a batch of these items (JSON-formatted source records) to Amazon Kinesis Firehose.
- Firehose is configured to deliver data it receives into S3 bucket. Kinesis Data Firehose converts your JSON-formatted source records using a schema from a table defined in AWS Glue Data Catalog.
- Firehose delivers all transformed records into an S3 bucket in Apache Parquet output format.
- Run another AWS Glue crawler pointing to data store (S3 bucket) to create table definition based on the S3 partitioned data.
- Run Athena standard SQL queries to analyse S3 data.
- Then Connect Power BI to Athena and generate report using Athena as data source.
Step 1: Activate DynamoDB Streams on your DynamoDB table.
Follow the steps to enable DynamoDB Streams – how-to-activate-dynamodb-streams-on-your-dynamodb-table/
Step 2: Setup AWS Glue Crawler to crawl DynamoDB Table
Follow the steps to setup AWS Glue crawler for DynamoDB data store – how-to-create-aws-glue-crawler-to-crawl-amazon-dynamodb-and-amazon-s3-data-store/
Step 3: Create Firehose delivery stream to load the data into S3.
Follow the steps to create Kinesis Firehose delivery stream – how-to-set-up-the-amazon-kinesis-firehose-delivery-stream/
Step 4: Create lambda function to buffer items newly added to the DynamoDB table and sends a batch of these items (JSON-formatted source records) to Amazon Kinesis Firehose
Now create test data in DynamoDB Table, the data will flow through DynamoDB Stream –> lambda function –>Kinesis Firehose –> S3 bucket. Once data is available in S3 bucket then run step 5 to run crawler on this S3 to create database schema for Athena queries.

More details (errors etc) can be checked in CloudWatch logs

Step 5: Setup AWS Glue Crawler to crawl S3 data
Follow the steps to setup AWS Glue crawler for S3 data store – how-to-create-aws-glue-crawler-to-crawl-amazon-dynamodb-and-amazon-s3-data-store/
This step will create s3-database and s3_dynamodb_to_s3_records table schema in Data Catalog with partitions which will be used in Athena to query the data from S3 bucket.
Step 6 – Setup Athena to query data in S3 bucket
Open AWS Athena and select the S3-database and “s3-database”.”s3_dynamodb_to_s3_records” table. Run queries and create views. and save the views.

Step 7 – Connect MS Poswer BI to Amazon Athena using Athena ODBC driver
Follow the steps to connect-microsoft-power-bi-to-amazon-athena-using-athena-odbc-driver/